
CS336-1-基础部分
LLM的基础知识,包括Tokenization、PyTorch资源计算、LLM架构与超参数等内容。
1.Tokenization#
Tokenization是将文本分割成更小的单位(tokens)的过程,这些单位可以是单词、子词或字符。
BPE#
BPE(Byte Pair Encoding)是一种基于频率的子词分割方法。它通过迭代地合并最频繁出现的字节对来构建子词表。很古老的算法(94年),但是效果还不错。
字符到字节数字直接映射的代码实现
def char_to_bytes(text):
byte_array = text.encode('utf-8')
byte_list = list(byte_array)
return byte_listOriginal text: Hello, World!
Byte representation: [72, 101, 108, 108, 111, 44, 32, 87, 111, 114, 108, 100, 33]
Original text: 你好,世界!
Byte representation: [228, 189, 160, 229, 165, 189, 239, 188, 140, 228, 184, 150, 231, 149, 140, 239, 188, 129]然后BPE会基于这些字节进行子词的合并。
训练阶段:
1. 将所有文本用 char_to_bytes 转换为字节列表
2. 初始化为单个字节的token
3. 重复直到词汇表达到目标大小:
a. 统计所有相邻token pair的频率
b. 合并频率最高的pair
c. 更新整个语料
编码阶段:(这个在应用的时候用到)
1. 用 char_to_bytes 将输入文本转为字节
2. 应用所有训练好的合并规则
3. 返回token IDs和对应的字节对象完整的简易BPE编码器实现
class BytePairEncoder:
"""完整的BPE编码器实现"""
@staticmethod
def char_to_bytes(text):
"""将文本转换为UTF-8字节列表"""
return list(text.encode('utf-8'))
@staticmethod
def bytes_to_text(byte_list):
"""将字节列表转换回文本"""
return bytes(byte_list).decode('utf-8', errors='replace')
def __init__(self, vocab_size=1000):
"""
初始化BPE编码器
Args:
vocab_size: 目标词汇表大小(包括基础的256字节)
"""
# 基础词汇表:256个字节
self.base_vocab = {bytes([i]): i for i in range(256)}
self.reverse_base = {i: bytes([i]) for i in range(256)}
# BPE合并规则
self.merges = [] # 存储(byte1, byte2)合并规则
self.vocab = self.base_vocab.copy() # 完整词汇表
self.reverse_vocab = self.reverse_base.copy()
self.vocab_size = vocab_size
self.next_token_id = 256 # 新token从256开始
def train(self, corpus, verbose=False):
"""
在语料上训练BPE
Args:
corpus: 文本列表
verbose: 是否显示训练过程
"""
if verbose:
print(f"开始BPE训练,目标词汇表大小: {self.vocab_size}")
print(f"基础词汇表大小: 256")
print(f"需要学习 {self.vocab_size - 256} 个合并规则")
# 将语料转换为字节序列 - 使用类方法
tokenized_corpus = []
for text in corpus:
byte_list = self.char_to_bytes(text) # 改为self.char_to_bytes
# 转换为字节对象列表
tokens = [bytes([b]) for b in byte_list]
tokenized_corpus.append(tokens)
# BPE训练:迭代合并
merge_count = 0
while len(self.vocab) < self.vocab_size:
# 统计所有相邻pair的频率
pair_freq = {}
for tokens in tokenized_corpus:
for i in range(len(tokens) - 1):
pair = (tokens[i], tokens[i+1])
pair_freq[pair] = pair_freq.get(pair, 0) + 1
if not pair_freq:
if verbose:
print(f"没有更多可合并的pair,提前停止")
break
# 找到最常见的pair
best_pair = max(pair_freq.items(), key=lambda x: x[1])[0]
self.merges.append(best_pair)
# 创建新token
new_token = best_pair[0] + best_pair[1]
token_id = self.next_token_id
self.vocab[new_token] = token_id
self.reverse_vocab[token_id] = new_token
self.next_token_id += 1
if verbose and merge_count % 10 == 0:
print(f"合并 #{merge_count+1}: {best_pair} -> ID:{token_id}")
print(f" 新token: {new_token} (长度:{len(new_token)}字节)")
# 在语料中应用这个合并
new_tokenized_corpus = []
for tokens in tokenized_corpus:
new_tokens = []
i = 0
while i < len(tokens):
if (i < len(tokens) - 1 and
tokens[i] == best_pair[0] and
tokens[i+1] == best_pair[1]):
# 合并这一对
new_tokens.append(new_token)
i += 2 # 跳过已合并的第二个元素
else:
new_tokens.append(tokens[i])
i += 1
new_tokenized_corpus.append(new_tokens)
tokenized_corpus = new_tokenized_corpus
merge_count += 1
if verbose:
print(f"训练完成!共学习 {len(self.merges)} 个合并规则")
print(f"最终词汇表大小: {len(self.vocab)}")
return self.merges
def encode(self, text):
"""
使用训练好的BPE编码文本
Args:
text: 输入文本
Returns:
token_ids: token ID列表
tokens: 对应的字节对象列表
"""
# 1. 转换为字节列表 - 使用类方法
byte_list = self.char_to_bytes(text) # 改为self.char_to_bytes
# 2. 初始化为单个字节的token
tokens = [bytes([b]) for b in byte_list]
# 3. 按顺序应用所有合并规则
for pair in self.merges:
new_tokens = []
i = 0
while i < len(tokens):
if (i < len(tokens) - 1 and
tokens[i] == pair[0] and
tokens[i+1] == pair[1]):
# 合并这一对
new_token = pair[0] + pair[1]
new_tokens.append(new_token)
i += 2
else:
new_tokens.append(tokens[i])
i += 1
tokens = new_tokens
# 4. 转换为token ID
token_ids = [self.vocab[token] for token in tokens]
return token_ids, tokens
def decode(self, token_ids):
"""
将token IDs解码回文本
Args:
token_ids: token ID列表
Returns:
text: 解码后的文本
"""
# 1. 将IDs转换回字节
byte_sequence = b''
for token_id in token_ids:
if token_id in self.reverse_vocab:
byte_sequence += self.reverse_vocab[token_id]
else:
# 如果ID不在词汇表中,使用基础字节
byte_sequence += bytes([token_id % 256])
# 2. 解码为文本
try:
text = byte_sequence.decode('utf-8')
except UnicodeDecodeError:
# 如果有无效序列,使用错误处理
text = byte_sequence.decode('utf-8', errors='replace')
return text
def get_vocab_size(self):
"""获取当前词汇表大小"""
return len(self.vocab)
def print_vocab_sample(self, n=20):
"""打印词汇表示例"""
print("\n词汇表示例:")
print("-" * 40)
print(f"{'Token ID':<10} {'字节长度':<10} {'内容(可打印部分)'}")
print("-" * 40)
# 按ID排序
sorted_items = sorted(self.reverse_vocab.items(), key=lambda x: x[0])
for i, (token_id, token_bytes) in enumerate(sorted_items):
if i >= n:
print(f"... 还有 {len(self.vocab) - n} 个token")
break
# 尝试解码为可打印字符
try:
content = token_bytes.decode('utf-8')
display = repr(content)
except:
display = repr(token_bytes)
print(f"{token_id:<10} {len(token_bytes):<10} {display}")
print("-" * 40)
疑惑#
Q1: 汉字占用三个字节,其中的单个字节会被当做一个原来256范围内的token吗?
答案肯定是不会的。
首先,要搞懂字符到字节的映射关系,在UTF-8的编码中,ASCII字符使用单个字节表示,而非ASCII字符使用多个字节表示,比如汉字使用3个字节表示,即一个汉字使用三个数字表示。 具体的映射逻辑如下:
第一个字节的范围 含义
0xxxxxxx (0-127) ASCII字符(单字节)
110xxxxx (192-223) 双字节字符的起始字节
1110xxxx (224-239) 三字节字符的起始字节
11110xxx (240-247) 四字节字符的起始字节
10xxxxxx (128-191) 多字节字符的后续字节这里类似哈夫曼编码。
大语言模型的tokenizer会有海量的训练数据,BPE会基于这些数据学习到常见的字节组合,从而形成子词token。因此,汉字的三个字节会被BPE合并成一个token,而不是单独作为三个token处理。这里由于是大量的数据,因此也不用担心学不到。
2.PyTorch, resource accounting#
全连接神经网络的粗略估算:前向传播的计算量是参数量的2倍左右,反向传播的计算量是前向传播的2倍左右,即参数量的4倍左右,总的计算量大约是参数量的6倍左右。还需要乘以输入的长度。因此在一个step中,FLOPs的计算公式大约是:
3.Architecture of LLMs and hyperparameters#
3.1 LLM的组件#
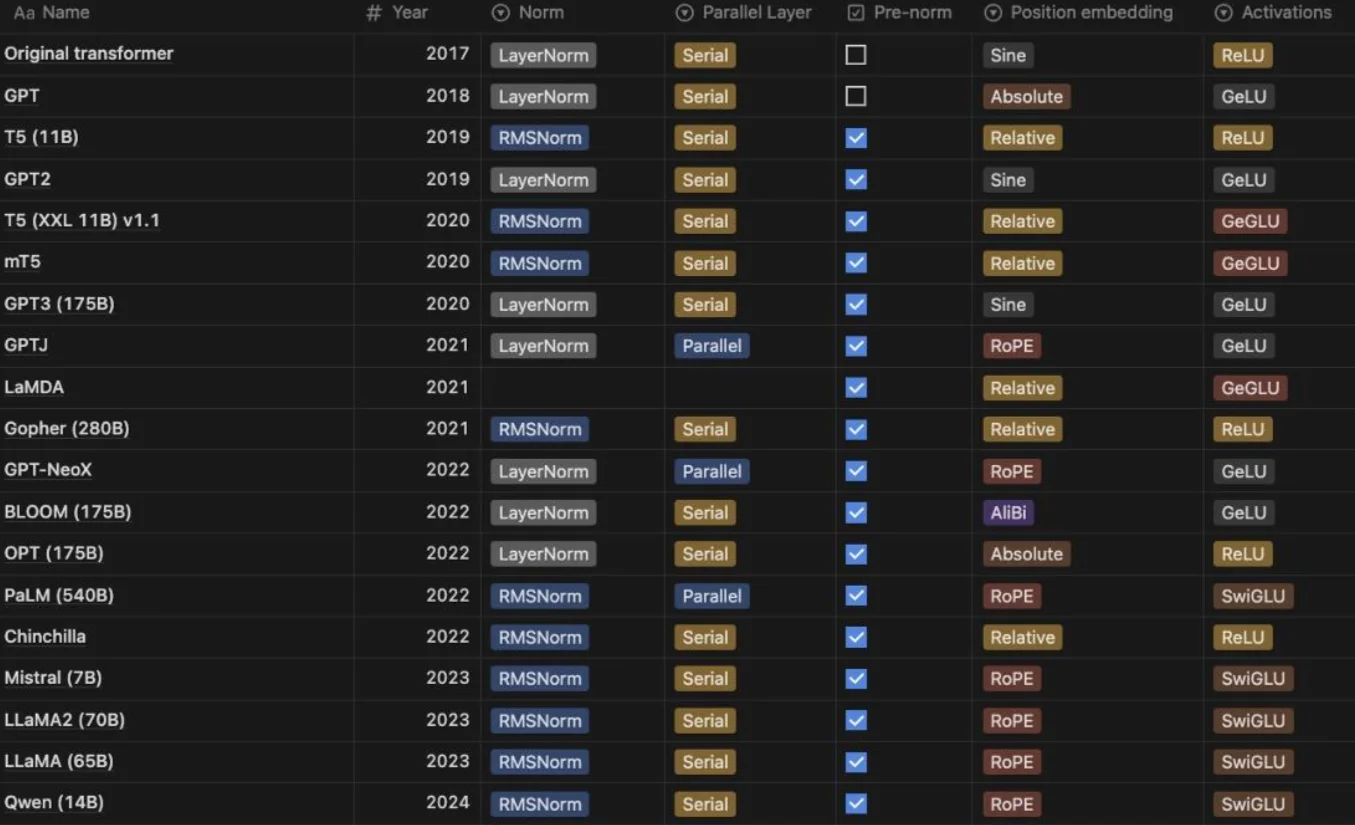
- pre norm vs post norm
现在大多数模型都采用pre-norm结构,因为它在训练深层网络时更稳定,让梯度直接回传到原始输入,不经过 norm的干扰。
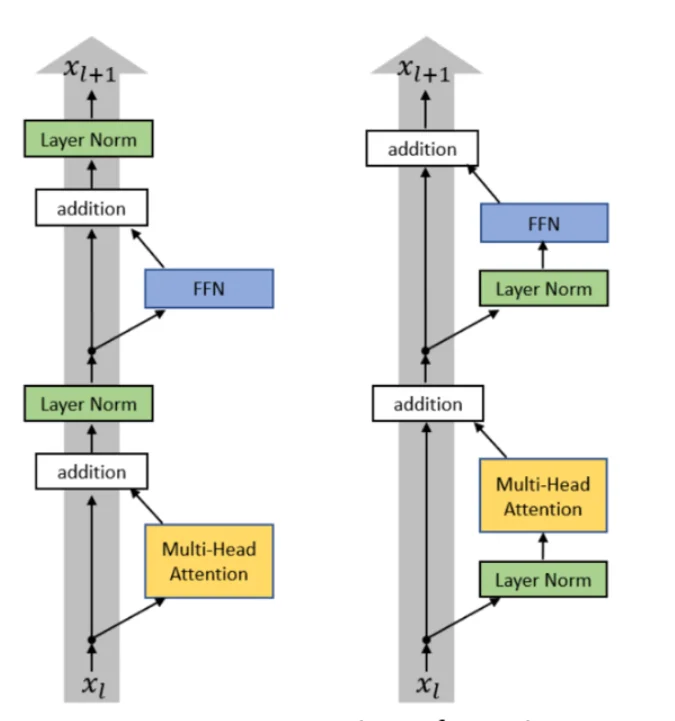 2. LayerNorm vs RMSNorm
2. LayerNorm vs RMSNorm
LayerNorm是对每个样本的所有特征进行归一化,而RMSNorm只使用均方根(RMS)来归一化,不减去均值,并且不加偏置。RMSNorm计算更简单,更快,节省内存,而且效果基本相当。
- 激活函数
- ReLU
- GeLU
- GeGLU
- SwiGLU
GeLU是ReLU的平滑版本,然后其中的 表示逐元素相乘。GeGLU和SwiGLU是Gated Linear Unit的变体,通过引入门控机制来增强模型的表达能力。
现在大多数LLM都使用SwiGLU作为激活函数,它在实践中表现出更好的性能。
- Serial vs Parallel
这里的串行与并行指的是两个线性层的计算逻辑,并非是CUDA加速计算的并行。串行结构是传统的Transformer架构,层与层之间是顺序连接的。而并行结构则将注意力机制和前馈网络并行处理,然后将它们的输出进行融合。当前大模型大多采用串行结构,
#串行方式
h = activation(W1 * x + b1) # 第一层
output = W2 * h + b2 # 第二层(必须等第一层算完)
#并行方式
h1 = W1 * x + b1 # 第一层权重
h2 = W2 * x + b2 # 第二层权重(与第一层同时计算)
output = activation(h1) * h2 # 然后组合现在LLM采用串行,主要是Serial的稳定性优势 > Parallel的微小延迟优势,
- 位置编码
- 绝对位置编码(Absolute Position Encoding):为每个位置分配一个唯一的编码,模型通过这些编码来识别序列中的位置关系。常见的方法有正弦-余弦位置编码(Sinusoidal Position Encoding)和可学习的位置编码(Learnable Position Encoding)。
- 相对位置编码(Relative Position Encoding):相对位置编码关注的是序列中元素之间的相对位置关系。
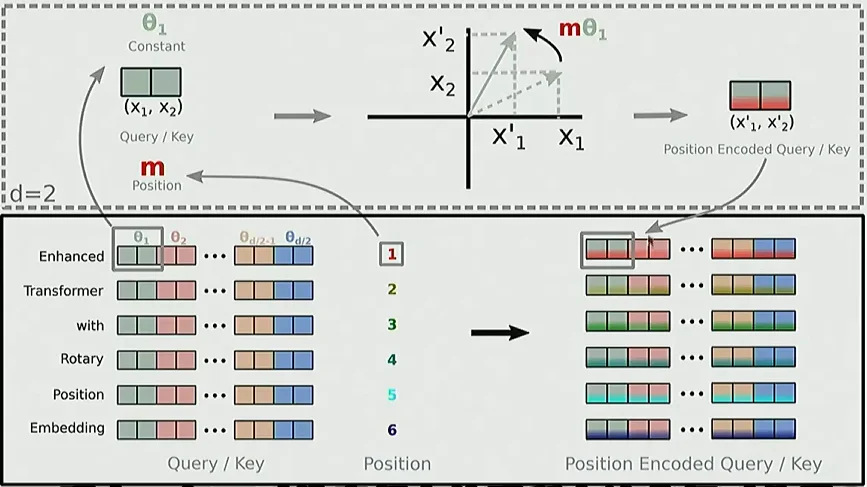
- Rotary Position Embedding (RoPE):RoPE通过旋转嵌入向量来编码位置关系,使得模型能够更好地捕捉序列中元素之间的相对位置关系。RoPE在实践中表现很好,已经被广泛应用于各种大语言模型中。
 RoPE的处理是在高维空间中的旋转是通过切分成多个二维平面来实现的。每个二维平面对应嵌入向量的两个维度,通过在这些二维平面上应用旋转矩阵来实现位置编码。
RoPE的处理是在高维空间中的旋转是通过切分成多个二维平面来实现的。每个二维平面对应嵌入向量的两个维度,通过在这些二维平面上应用旋转矩阵来实现位置编码。
3.2 超参数#
- 与
前馈网络的隐藏层维度 通常设置为模型维度 的4倍,即 。这是对于Relu等激活函数的常见设置。然后如果使用SwiGLU等激活函数,通常设置为 ,这是让参数量相等的数学结果。
- 注意力头数 、每个头的维度 与模型维度
模型维度 通常被划分为多个注意力头,每个头的维度为 。头数 和每个头的维度 之间存在一定的关系。
定义,通常这个比率为1(当然也有不为1的情况),即
- 与层数
模型维度 和层数 之间存在一定的经验关系。通常,较大的模型维度需要更多的层数来充分利用其表达能力。
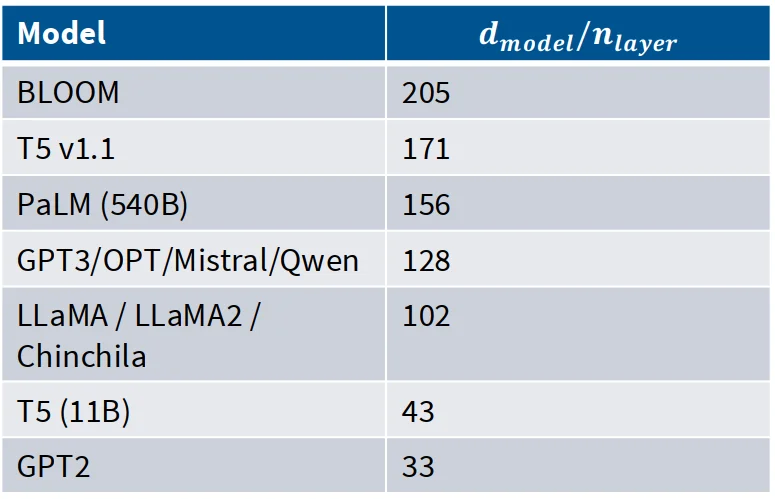
- 词汇表大小
词汇表大小 与模型是否为多语言模型有关。对于单语言模型,词汇表大小通常在30,000到50,000之间。而对于多语言模型,词汇表大小可能需要更大,以覆盖更多的语言和字符集,通常在100,000以上。
- 正则化
正则化技术如Dropout和权重衰减在大语言模型中也很重要。Dropout通常设置在0.1到0.3之间,而权重衰减的值通常在1e-5到1e-2之间。而且大多数LLM都不使用Dropout,使用权重衰减。
3.3 最新的训练稳定的trick#
后续ing